
Why future AI agents will be trained to work together
Many multi-agent setups are based on fancy prompts, but this is unlikely to persist
We’re moving towards a world where multi-agent systems will be near-ubiquitous, and where they won’t just look like prompt engineering on steroids.
Over the last few years, we’ve increasingly seen AI systems spin up multiple LLM instances to solve problems. OpenAI has a multi-agent team which was involved in their recent IMO gold medal.1 Grok 4 Heavy involves multiple agents working in parallel on the same task. Claude Research coordinates multiple instances of Claude 4. Claude Code uses the Task tool to delegate subtasks to subagents. And over the last year, all of OpenAI, Anthropic, and Google DeepMind have had job postings looking for expertise in multi-agent systems.
We expect this trend toward multi-agent systems to continue: as task lengths increase, the benefits of parallelization will become too large to ignore. Importantly, while these LLM instances will work in parallel, they often won’t work independently: they'll need to coordinate to avoid stepping on each other's toes, and performance improves when they can share key context and learnings. Currently, this coordination is often handled by hardcoding specific roles for different subagents. But we expect this approach to fade away, replaced by models natively trained to spawn and coordinate arbitrary instances as needed.
The enormous gains from parallelization
The core reason we expect multi-agent systems to become more widespread is that for many tasks, having LLM instances working in parallel is extremely beneficial: it improves accuracy and reliability, saves wallclock time, and reduces memory footprint.
First, having LLM instances work in parallel can improve models’ ability to solve harder tasks. For example, Claude Research’s multi-agent setup outperformed single-agent Claude Opus 4 by 90.2% on Anthropic’s internal research eval. On complex problems, it helps to have multiple LLMs testing various strategies, since it’s hard to predict all the required solution steps in advance. Current products such as Grok 4 Heavy and GPT-5 Pro show more impressive performance and higher reliability than their single-instance counterparts.
Many of these improvements are due to multi-agent systems using more tokens than their single-instance counterparts. For example, Claude Research’s multi-agent setup uses 3.75x more tokens compared to a single agent, and 15x more than a simple chat dialogue. This gets at the advantage of launching multiple agents: using the same number of tokens within a single context would require long-context abilities that language models currently lack. And even if models have sufficiently large context windows in practice, it is still helpful to adopt more modular contexts. For example, consider the LoCoDiff benchmark, where near overlap of codebases over long contexts can confuse LLMs. For this reason, spinning up multiple LLMs makes it possible to usefully scale the number of tokens further.
Second, when a task splits into multiple subtasks, performing these subtasks in parallel can save a lot of time. For example, parallel tool calling in Claude Research “cut research time by up to 90% for complex queries, allowing Research to do more work in minutes instead of hours”. And you can easily imagine this applying to other tasks too: why waste your time responding to your emails individually, if you can make a 100 copies of yourself and do it in parallel?
Crucially, performing tasks more quickly is good for impatient users. But it’s also helpful for AI developers because it means faster iteration cycles and hence algorithmic progress. It’s hard to improve your reward model or data mixture if it takes several days to test how it impacts model quality. This is becoming increasingly important as LLMs learn to perform tasks with longer horizons, and as they use more tokens to solve tasks sequentially.
Relatedly, parallelizing helps use available memory more efficiently at inference time, such as by preventing KV-caches from blowing up. For instance, consider a task which requires doing five subtasks that can be performed independently. If we do them in sequence, by the time we get to the fifth subtask the model’s KV-cache will contain the keys and values for all the tokens involved in solving the first four subtasks. This is extremely wasteful relative to solving the five subtasks in parallel.
A factor pushing against this trend toward the widespread use of multi-agent systems is cost. Since multi-agent systems perform better by usefully consuming more tokens than querying a single LLM instance, customers might prefer paying less even if it leads to lower quality outputs. We agree that this is a concern for some tasks, such as consumer facing products where users are highly price-sensitive and don’t derive a lot of value from higher-quality responses. However, we believe there will be many tasks that are sufficiently economically valuable and amenable to multi-agent systems, such that the benefits of multi-agent setups outweigh the costs. Coding is a particularly prominent example of this, since it comprises the bulk of current LLM use, is worth hundreds of billions of dollars each year, and is also a primary focus for practically all frontier AI companies. Even today, products like Claude Code are based on multi-agent setups, and we expect something similar to be true going forward.
Another potential limitation is that multi-agent systems only offer large gains on tasks that can be decomposed into subtasks that don’t require a lot of shared context. What fraction of tasks have such structure is an open problem. However, we believe that the majority of economically relevant tasks can be decomposed in this way, especially since as we will see in the next sections, subagents need not operate completely independently, and can occasionally share relevant context.
Parallel LLM instances will interact and coordinate
Most of the multi-agent systems that we’ve looked at so far have not required a huge amount of coordination between agents. In the case of Grok 4 Heavy and o3-pro, multiple instances are spun up, but each instance solves the same task. In the case of Claude Research, different agents solve different subtasks, but they don’t have side effects on a shared environment.
One exception to this is Claude Code. In this case, each instance of Claude can take actions that change the repository it’s editing, potentially leading to conflicts with the actions of other instances. In cases like these, it’s going to be very important for agents to avoid stepping on each others’ toes. And while it’s possible to use hacky workarounds to this problem in coding,2 this is a challenge that extends to other domains – coding is simply a leading indicator. Future agents may need to coordinate when working simultaneously on an excel file, on Figma, or other computer tasks.
Even if we ignore problems from stepping on each others’ toes, it is likely beneficial for agents to interact and share ideas. When solving problems, agents can try different approaches, and share information about which approaches are more or less promising.
As a result, future agents won’t operate independently. As we’re already seeing in code, agents will need to coordinate to avoid interfering with each other, and they’ll also benefit from communicating and occasionally sharing relevant context.
Moving away from hard-coded multi-agent systems
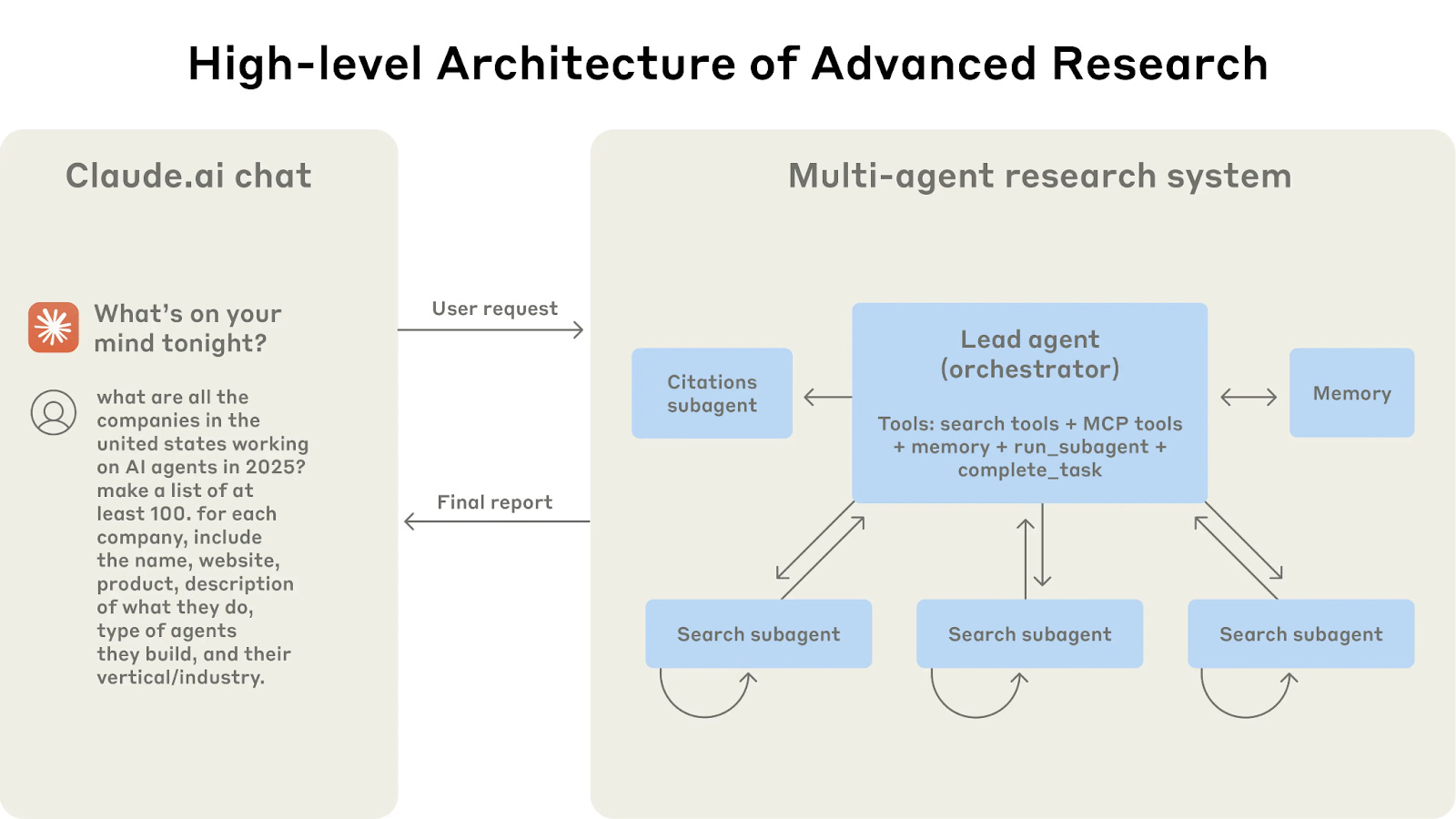
So we’ve established that the gains from multi-agent setups could be huge, and that we should expect subagents to interact, coordinate and avoid interfering with each other even as they operate simultaneously in a shared environment. Currently, this often happens via fancy scaffolds that precisely specify subagents’ roles and affordances, but we doubt that this will last for very long.
To see what we mean, we yet again consider Anthropic’s Claude Research. To coordinate the multiple instances of Claude, Anthropic used heavily engineered prompts. For example, it manually specifies the roles of specific agents, such as the “citations subagent” and “search subagent” roles. And rather than letting a “lead agent” choose how many agents to spawn for some task, the prompt explicitly hardcodes how many agents to spin up:

Rigid setups like this probably aren’t going to persist. With models like GPT-4, we used to use contrived prompts like “let’s think step by step”, but the need for this has been obviated by training that improves model capabilities. In much the same way, we just shouldn’t expect hacky prompts like this to last. That’s not persisted historically, and we shouldn't expect multi-agent LLM setups to be different.
Part of the reason for this is that we expect labs to continue scaling compute. They’re already throwing large amounts of labor and compute at trying to improve these models, and some of this will likely be devoted to training instances to interact with each other. This way, models can learn to coordinate without stepping on each others’ toes, or without the tendency to spin up 50 agents on simple tasks. We think this is likely part of what Noam Brown means by getting multi-agent RL research to internalize the Bitter Lesson. You just need a good amount of compute and trial-and-error.
The other part of this is that moving away from these hard-coded prompts helps make multi-agent setups more dynamic. For labs to be able to truly capitalize on the gains from multi-agent setups, they want to be able to leverage it in a wide range of real-world circumstances, many of which won’t be obvious at first glance. This means letting LLM agents choose how many subagents (and of what type) to spawn, how to partition tasks, how to deal with conflicts between interacting agents, and so on. In the long run, these choices will be most effectively determined by agents that have the relevant information about the task, not by specifying it in advance.
The upshot is that we’re getting more and more multi-agent LLM setups, and the most important of these setups to pay attention to are the ones without hard-coding. The gains from such a transition could be huge, at least on some tasks. Especially with recent works on multi-LLM settings by multiple frontier AI labs, we wouldn’t be surprised to see major announcements from these labs in the next year or two, where LLMs have explicitly been trained to coordinate with each other.
In the long run, things become substantially more uncertain. So far, we’ve largely focused on systems of multiple agents from the same provider (or the same user) coordinating with each other. But future dynamics could be vastly more complicated, involving agents from different labs with competing interests. It also becomes increasingly unclear how to best exploit the gains from parallelization – for instance, it is hard to rule out the possibility of future model architectures that do this more natively. However, we think that the most straightforward continuation of existing trends is this: existing rigid multi-agent frameworks will fade away. Instead, we’ll likely have multiple agents learn to coordinate and interact, at least for the next 1-2 years.
That said, it’s not clear whether the gold medal was really due to the use of multi-agent setups, or this year’s competition problems being easier than usual.
For example, it’s possible to use git worktrees or split work between editing different files.
Will this require a special kind of training to build a hive-mind that can knock of ideas with other models and delegate tasks, similar to how human organizations work? Because most models today are tuned for chat training (+ tools, ofc), and the only thinking they do is their internal monologue.