



Why China isn’t about to leap ahead of the West on compute
Chinese hardware is closing the gap, but major bottlenecks remain
We keep hearing that China is catching up with the West in AI compute. A great example of this comes from NVIDIA’s CEO Jensen Huang, who recently claimed that China has made “enormous progress” in the last few years, and that “China is right behind us. We’re very, very close.”
And China has indeed been making a ton of progress. As we’ll see, Chinese hardware has been closing the gap across a range of metrics relating to computational power and data transfer, both of which are crucial aspects of AI workloads.
But despite progress on these metrics, we don’t think China is about to leap ahead of the West on AI compute. China’s top developers—including Alibaba, ByteDance, Baidu, and DeepSeek—still rely primarily on NVIDIA chips. And major bottlenecks still remain before China can leap ahead.
The first bottleneck lies in chip manufacturing. U.S. export controls of chipmaking equipment make it more costly for China to produce chips at the massive scale needed for frontier model training and inference.
The second bottleneck lies in China’s weaker software ecosystem. Unlike NVIDIA’s CUDA stack, Chinese chips operate in ecosystems that are bug-prone, poorly-documented, and unstable.
As a result, we think that Chinese developers will continue to prefer to train their models on Western chips when available, for at least the next few years. However, this does not preclude them training on less-performant Chinese chips with a cost penalty, when Western chips are hard to acquire.
On paper, China’s hardware is closing the gap
AI developers want to train and run better AI systems, and a huge part of this is using better AI hardware. This means using more powerful chips and better infrastructure to move around large amounts of data.
What we’ve seen over the last few years is that while Western hardware remains better along these dimensions, Chinese hardware is closing the gap.
Take computational power as an example. Since 2017, the floating-point operations per second (FLOP/s) of both Chinese and non-Chinese chips have grown exponentially.1 Whereas there was an order of magnitude gulf between Chinese and Western silicon in 2018, this difference has shrunk to 3x today, the gap between China’s leading Huawei’s Ascend 910C GPU and NVIDIA’s B200, the leading Western GPU.2 Chinese chips even briefly held the lead with the release of the BR100 datacenter GPU, which was allegedly the fastest chip on the market at the time of release.3
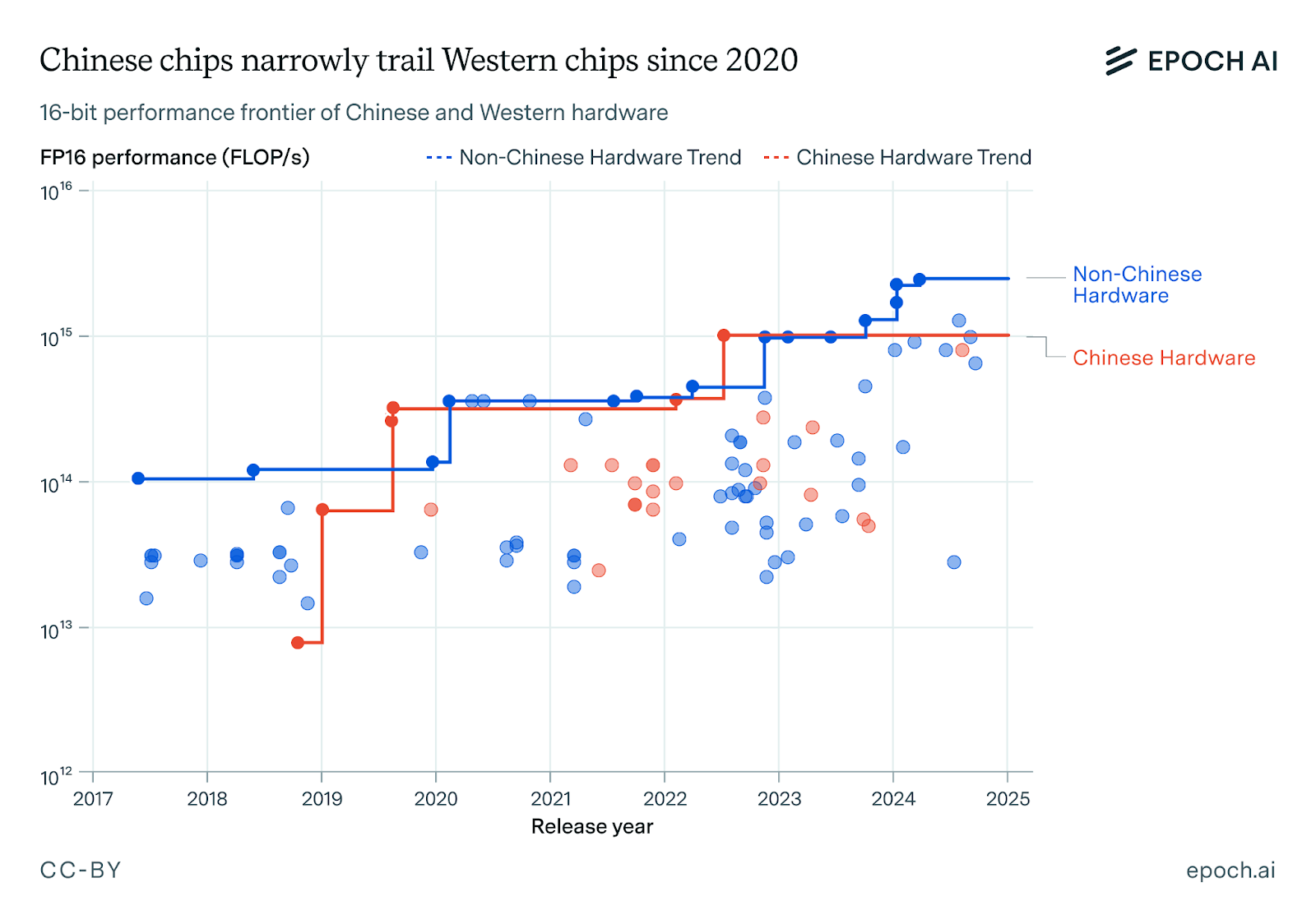
Even if we account for the costs of computation, we see a similar pattern. Chinese hardware has historically been cost-competitive with Western hardware, albeit available only in lower quantities. For example, although Huawei’s Ascend 910B was 3x weaker than NVIDIA’s H100 in computational performance, it was also 3x cheaper. Since these two GPUs were released in 2022, they had equal price-performance in the same year.4
But focusing on computational operations is only half the story. For a fair comparison of Western and Chinese hardware, we also need to consider how well this hardware transfers data. This is crucial because AI workloads generally involve a huge amount of data processing across various hardware components.
One way this happens is through moving data between a chip’s memory and its compute units. The maximum rate that this data transfer can occur is called the memory bandwidth, and is especially important for running AI systems on long-context inputs or outputs.
On this metric, we also see Chinese hardware closing the gap. Western chips currently have the lead, with NVIDIA’s B200 currently having almost double the memory bandwidth of Huawei’s Ascend 910C.5 But Chinese chip memory bandwidth has improved at a rate of about 24% per year from 2017 to 2025, outpacing the roughly 13% annual gains seen by non-Chinese peers over the same period. If this rapid improvement is sustained, we could see parity in memory bandwidth as soon as the next generation of devices,6 though recent export controls on high-bandwidth memory present roadblocks to this.
The other crucial dimension of data transfer happens between chips. The maximum rate of this transfer, the interconnect bandwidth, needs to be high so that chips don’t spend too much time waiting for data during training.
As with the other metrics, Western hardware is currently in the lead. NVIDIA’s custom NVLink technology is over ten times faster than the PCIe 4.0 standard used with the Ascend 910C.7 To address this, Huawei has recently developed its own custom technology called the Unified Bus, used to link a network of chips in its CloudMatrix 384 system. Although this custom network reaches less than half the bandwidth of NVLink, and is less tightly coupled and not as well-supported by mainstream machine learning frameworks as NVIDIA’s interconnect stacks, the trend remains the same: Chinese hardware is catching up.
China still has to overcome major bottlenecks in domestic AI compute
In practice, reliance on Western chips persists
Despite all these improvements, and even with NVIDIA imports substantially restricted, domestic chips have never been predominant among leading Chinese AI developers.
One way to see this is to look at our data on notable Chinese machine learning models. Filtering down to the 130 language models released between 2017 and 2024, we see that over 90% of these models were trained on Western hardware.8
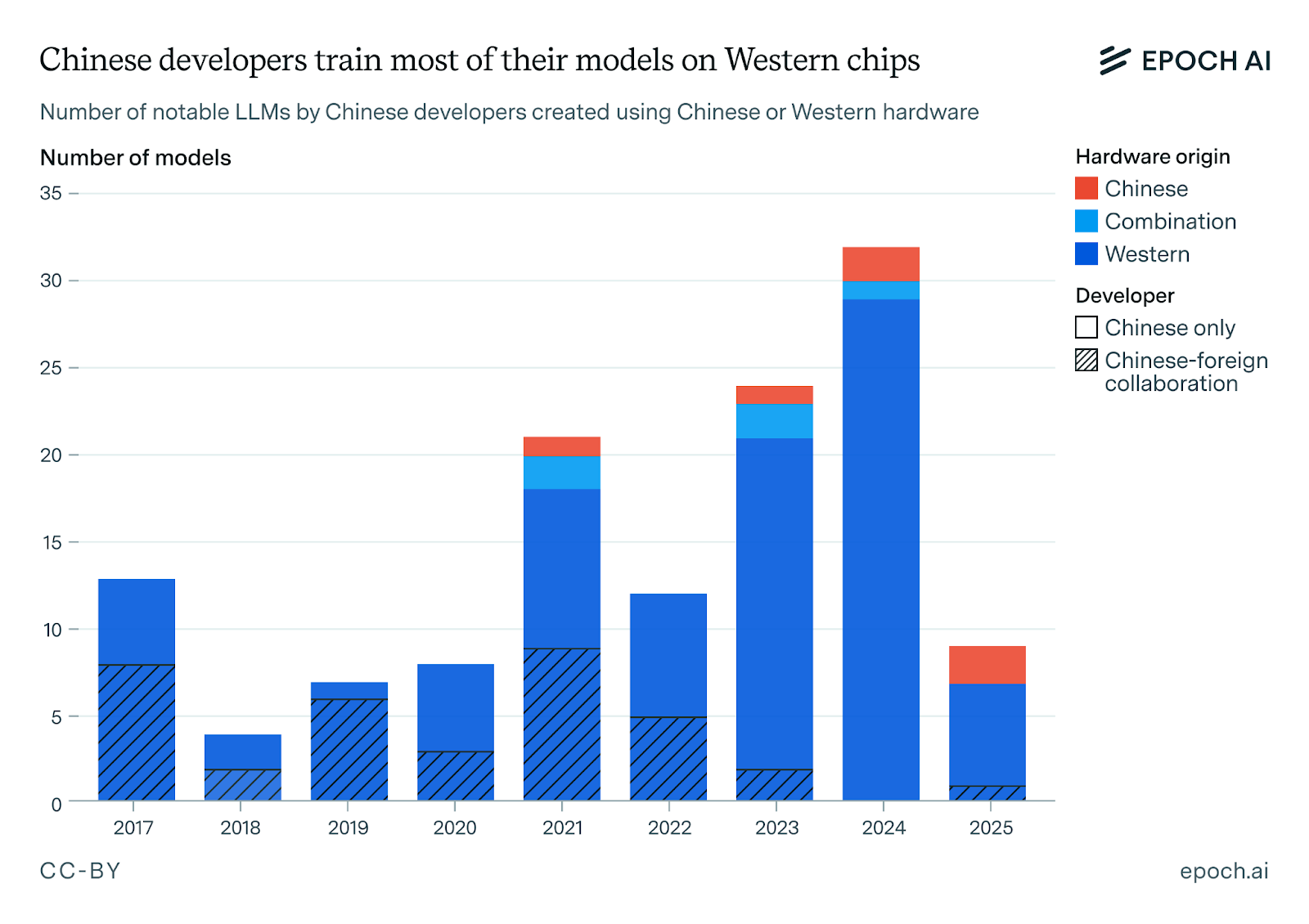
Even if we exclude joint ventures with U.S., Australian, or U.K. institutions (where the developers can access foreign silicon), the clear majority of homegrown models relied on NVIDIA GPUs. In fact, it took until January 2024 for the first large language model to reportedly be trained entirely on Chinese hardware, arguably years after the first large language models.9
Manufacturing Limitations and Export Controls
Probably the most important reason for the dominance of Western hardware is that China has been unable to manufacture these AI chips in adequate volumes. Whereas Huawei reportedly manufactured 200,000 Ascend 910B chips in 2024, estimates suggest that roughly one million NVIDIA GPUs were legally delivered to China in the same year. Most of these NVIDIA chips are H800 and H20 GPUs, which are less-performant than the best Western chips. Furthermore, tens of thousands of high-performance NVIDIA GPUs were likely smuggled via third-country or illicit channels. But they’re still clearly an attractive option for Chinese developers, as evidenced by the high number of orders from major Chinese AI companies, including ByteDance, Alibaba, and Tencent.10
Of course, Huawei is looking to expand its compute production to get around these bottlenecks. They are reportedly targeting 400,000 Ascend 910 (B and C) units in 2025, as well as potential new chips like the Ascend 920 that are slated to launch in the second half of 2025.11 However, this domestic supply is insufficient to train models on the frontier of scaling, since it is fragmented across various AI developers,12 and tends to be high in defects. These make large-scale training much more challenging, though not impossible, to achieve.
What makes China’s compute availability situation more challenging is the introduction of export controls over the last few years. Before these export controls, NVIDIA already dominated China’s AI compute with a 90% market share.13 Now China has to deal with restrictions on key inputs to chip production as well.
One such input to chip production is semiconductor manufacturing equipment (SME). One prominent example of such equipment is the advanced lithography machines used to etch circuit designs on semiconductor chips, which are almost exclusively made by the Dutch firm ASML. Without access to foreign SME, domestic Chinese manufacturers like SMIC are left playing catch-up.14 Consider that these chip manufacturing devices aren’t perfect, and only a fraction of produced chips actually work. This fraction, known as the “yield”, decreases when using worse equipment. So it’s no surprise that SMIC’s reported yields are below 50%, compared to TSMC’s 90%.15 Such low yields make these Chinese chips substantially less economically viable, requiring state support to alleviate this financial burden.16
These financial challenges are compounded by the other aspects of U.S. and Taiwanese export controls, which restrict TSMC from manufacturing advanced chips on behalf of mainland Chinese companies.17 U.S. export controls also effectively blacklist Chinese AI hardware use anywhere in the world. This makes it risky for Chinese companies to adopt Huawei chips, since they could face U.S. sanctions as a result.
Software Ecosystem Gaps
In addition to hardware challenges, Chinese AI chips exist within a much less mature software ecosystem than their Western counterparts.
On the one hand, we have NVIDIA’s CUDA, a software ecosystem for training across GPUs. This has benefited from over fifteen years of documentation and refinement, a large user base, and robust integration with popular machine learning frameworks like PyTorch and TensorFlow.
On the other hand, we have Huawei’s CANN framework. This was only introduced in 2019, twelve years after CUDA. And it’s often said by developers to be bug-prone, poorly documented, and unstable, with frequent runtime crashes and limited third-party integration.18
These issues don’t make it impossible for Chinese developers to perform large-scale training runs on Chinese hardware, but they certainly make it more costly. In fact, they have led many Chinese ML teams to adopt a hybrid approach: leveraging Huawei’s Ascend chips for inference workloads, while reserving their limited supplies of NVIDIA GPUs for large-scale training pipelines.19
Will China overcome these bottlenecks?
So far, we’ve argued that Chinese hardware has been catching up, but has only been used to a limited extent due to bottlenecks in chip manufacturing and the AI software ecosystem. This, however, leaves us with a big question: Will China overcome these bottlenecks in the near future?
Without access to advanced lithography equipment and the memory needed to create chips, Chinese manufacturers will be playing catch-up against the West. Even if export restrictions are alleviated, the immaturity of Chinese accelerator software ecosystems poses another serious bottleneck. China is trying to achieve parity in software and indigenize its supply chain, but even with massive subsidies, each roadblock will require years of work to overcome.
Put bluntly, we don’t see China leaping ahead on compute within the next few years. Not only would China need to overcome major obstacles in chip manufacturing and software ecosystems, they would also need to surpass foreign companies making massive investments into hardware R&D and chip fabrication. Unless export controls erode or Beijing solves multiple technological challenges in record time, we think that China will remain at least one generation behind in hardware. This doesn’t prevent Chinese developers from training and running frontier AI models, but it does make it much more costly. Overall, we think these costs are large enough to put China at a substantial disadvantage in AI scaling for at least the rest of the decade.
Thanks to Tharin Pillay, Lynette Bye, and Anson Ho for editorial suggestions, and Erich Grunewald, Mary Clare McMahon, and Yafah Edelman for helping to refine our research and takeaways.
Appendix
Table 1: timeline of leading Western and Chinese chips in each year.
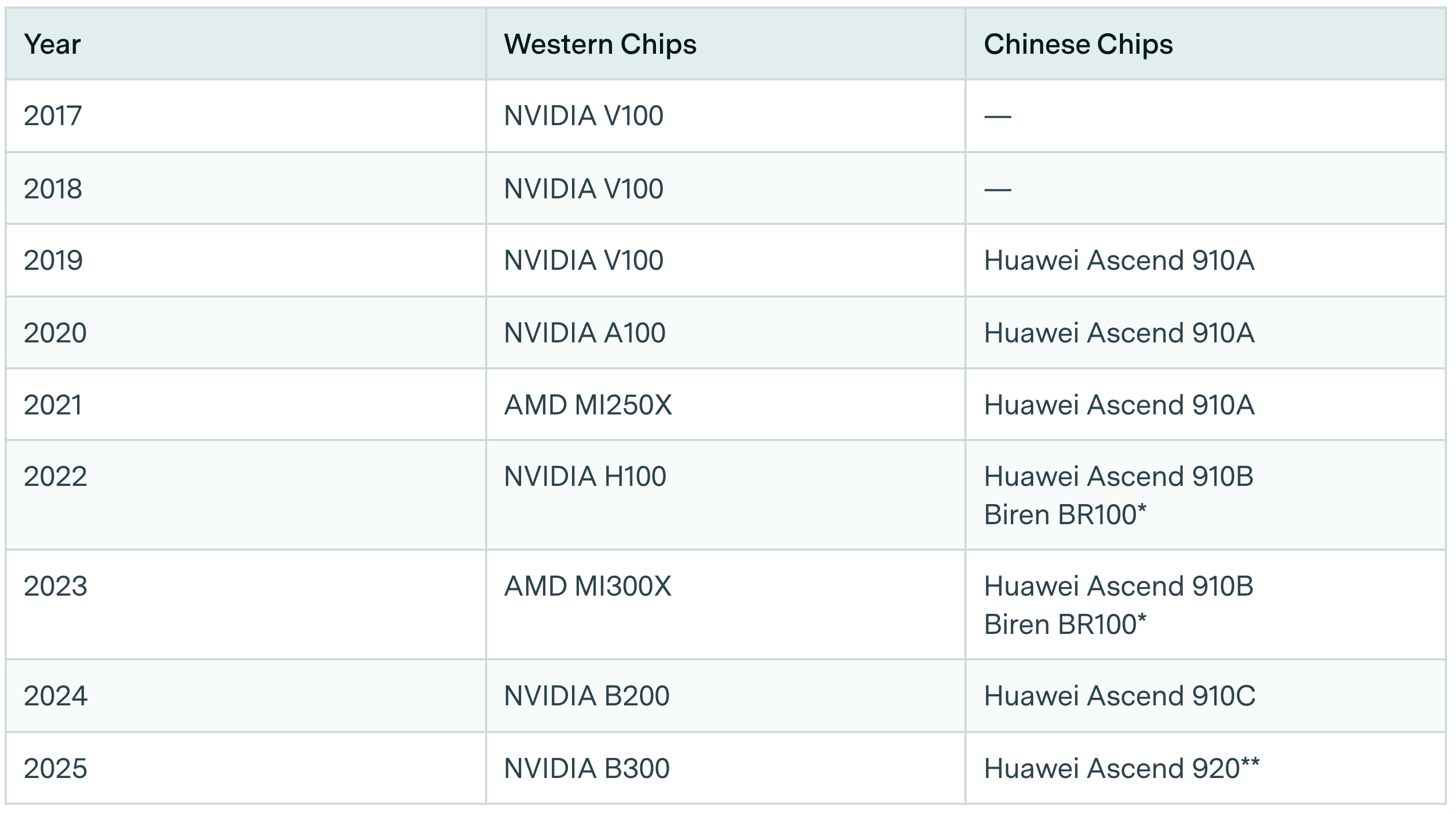
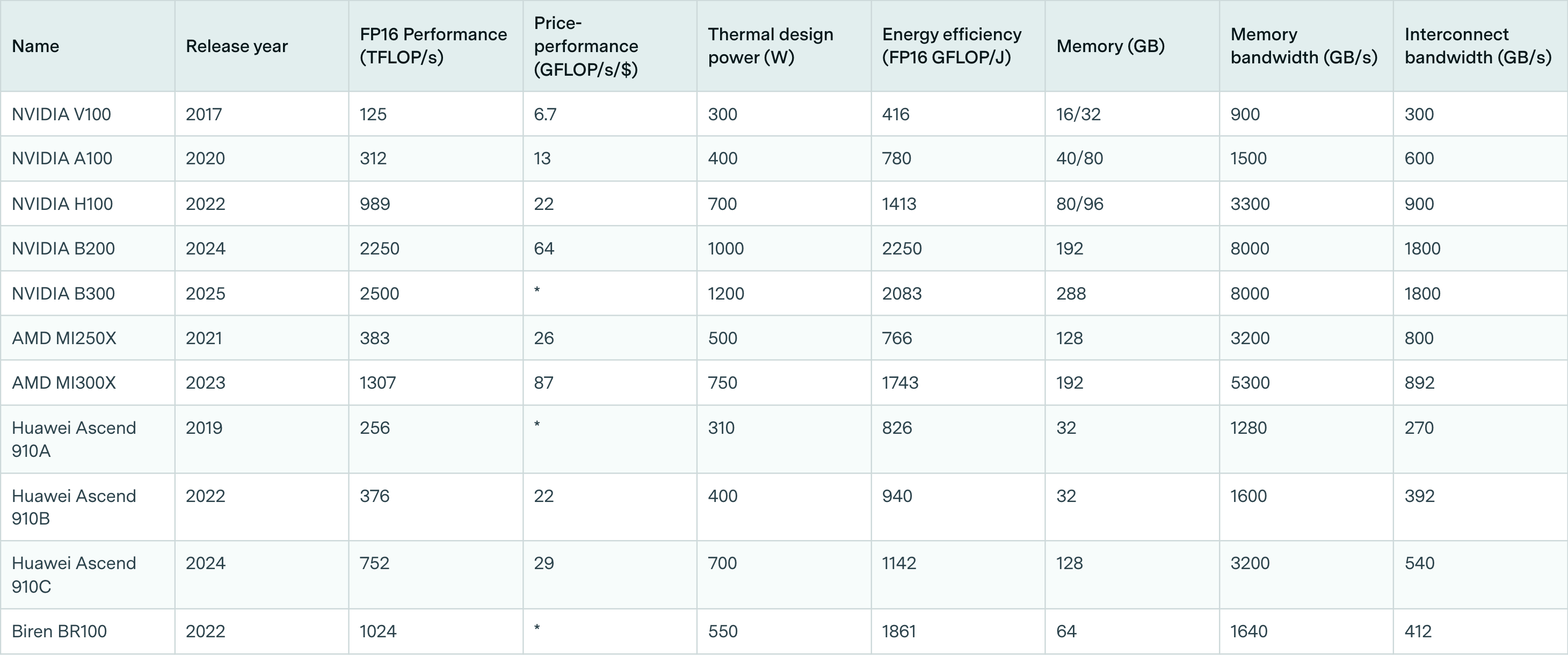
Table 2: specifications of selected ML hardware.20
See more regarding the trends in computational performance of machine learning hardware in this data insight.
Note that it soon trailed in performance compared to NVIDIA’s H100 GPU. Benchmark trials by SemiAnalysis found that H100s achieve 700-750 TFLOPS on dense matrix multiplications in BF16 arithmetic format, about 70-75% of its theoretical maximum BF16 performance. Based on DeepSeek's testing, Huawei’s Ascend 910C processor—currently the most advanced chip manufactured in China—reached about 60% of Nvidia's H100 performance, which would equal approximately 593 TFLOP/s, representing about 80% of the Chinese chip’s theoretical ceiling of 752 TFLOP/s.
{kind=link}
Compared with the H100, which was released around the same time, the Ascend 910B has lower total performance (376 vs 989 TFLOP/s) and memory bandwidth (1.6 vs 3.3 TB/s), but priced at ¥120,000 (around $16,000) versus the H100’s original retail price of $44,000, the chips had equal price-performance at 2.2×1010 FLOP/s per dollar. However, note that the lower memory and interconnect bandwidth of the Ascend 910B mean that it is less usable for scaled-up modern workloads than the H100, and therefore less useful after 2022.
Specifically, NVIDIA’s B200 chip offers a memory bandwidth of 8 terabytes per second (TB/s), while Huawei’s Ascend 910C has a memory bandwidth of about 3.2 TB/s.
We should also note that raw memory bandwidth only tells half the story. The ratio of bandwidth to memory is important because many ML kernels—optimizer updates, sparse embeddings, attention layers—are memory-bound, so their sustained FLOP/s is capped by their relative bandwidth per GB of memory. Chinese and western chips had historically similar ratios, but the latest domestic chips are inferior to Blackwell on this metric, and will need to improve if they are to be used at a scale matching the largest NVIDIA clusters.
NVLink lets NVIDIA GPUs share data at up to 900 GB/s per chip. In comparison, the common PCIe 4.0 standard only moves data between chips at 64 GB/s.
So far, DeepSeek—probably the most often referenced Chinese LLM—has also used NVIDIA GPUs to train its LLMs. Some social media posts rumored that R2 was trained on Ascend 910B but such claims have not been confirmed.
These H20 orders were frozen as the U.S. Department of Commerce imposed a licence requirement for the exports in April 2025. In July 2025, Nvidia announced that it will be granted licenses to resume sales of H20 to China. This was preceded by CEO Jensen Huang personally lobbying President Trump, warning that Nvidia would lose US $5.5 billion and that continued chips exports are needed for the U.S. to maintain AI leadership.
Actual production may be even lower than targeted, as industry sources believe that SMIC’s yield rate is worse than estimated by the FT.
In theory, these chips can collectively perform 1028 floating-point operations per year, but with the Chinese AI industry heavily fragmented between dozens of developers, a substantial portion of compute dedicated to inference, and historically poor model FLOP utilization in large clusters of Huawei chips, Ascend processors are likely not sufficient to create leading models. Chinese state media often describe the situation as a “Hundred Model War”, which refers to the high number of companies involved in LLMs development. Baidu’s CEO already warned that China has too many LLMs and the companies should focus more on their applications.
Conservatively assuming that the leading developer in China purchases 20% of the supply of Huawei chips produced in 2025, all of them are Ascend 910C, half are allocated to training in a single cluster, and they achieve 40% utilization in a 3-month training run, this would produce a model trained with 1×1026 FLOP by Q2 2026, about one year behind U.S. developers. In reality, the market is more fragmented, most compute is dedicated to inference, developers deploy many separate clusters, and suitably high utilization has never been demonstrated on more than 8,192 Huawei processors.
NVIDIA CEO Huang Jensen mentioned in May 2025 that NVIDIA’s share in the Chinese market dropped to 50%.
Although Huawei and Semiconductor Manufacturing International Corporation (SMIC) are independent companies, the pressure of the U.S. export controls have made them mutually indispensable, forming a key pillar for China’s semiconductor ambitions. Huawei, cut off from its previous cooperation with TSMC, is one of SMIC’s most important clients. SMIC now manufactures most of Huawei’s chips (including datacenter Ascend, mobile Kirin, and joint plans to manufacture 3 nm chips), and they also cooperate in R&D.
Here we are comparing yields specifically at the 7nm process, and in general the yield will depend on the specific design and specifications of the chip.
In 2017, China’s “New Generation Artificial Intelligence Development Plan” identified hardware as one of China’s weak points for becoming a dominant player in the AI field by 2030. Since then, the Chinese government has put a lot of investment into building domestic semiconductor capabilities and reducing reliance on foreign hardware. This includes a mix of gigantic investment funds and subsidies, with SMIC receiving a significant amount of state support, while Beijing urges Chinese companies to adopt domestic chips.
In spite of the export controls, TSMC-manufactured chips likely ended up in Huawei’s AI processors. TSMC is currently under investigation for potentially violating the controls, which could lead to over $1 billion in fines. These chips were officially made for Chinese firm Sophgo, but reverse-engineering revealed they matched those used in Huawei’s Ascend 910B, suggesting a covert supply chain route. TSMC has halted shipments to Sophgo, reported the issue to authorities, and maintains it has complied with all regulations. It is estimated that TSMC manufactured and shipped over 2 million Ascend 910B logic dies to various Huawei shell companies after the imposition of the export controls.
To overcome CANN’s performance and stability hurdles, Huawei has been dispatching teams of engineers to major customers—including Baidu, Tencent and iFlytek—to help port their CUDA-based training code to the CANN stack and keep deployments running.
For example, ByteDance and Tencent mentioned that they plan to use Huawei chips for inference and allocate their NVIDIA chips for training purposes. Huawei itself has underlined its strategy to focus on dominating China’s inference rather than new LLM training. Although Huawei has trained some language models using Ascend chips, all of their publicly disclosed runs have involved a much smaller number of chips compared to frontier training—only several thousand, compared to hundreds of thousands.
Price-performance calculations use release prices of the hardware, if available, which includes all NVIDIA chips except the B200. For chips whose prices are not published, we use estimates from public sources.
|
 | A guest post by
|
Great topic and coverage.