
What's the best model you can run on a single consumer GPU?
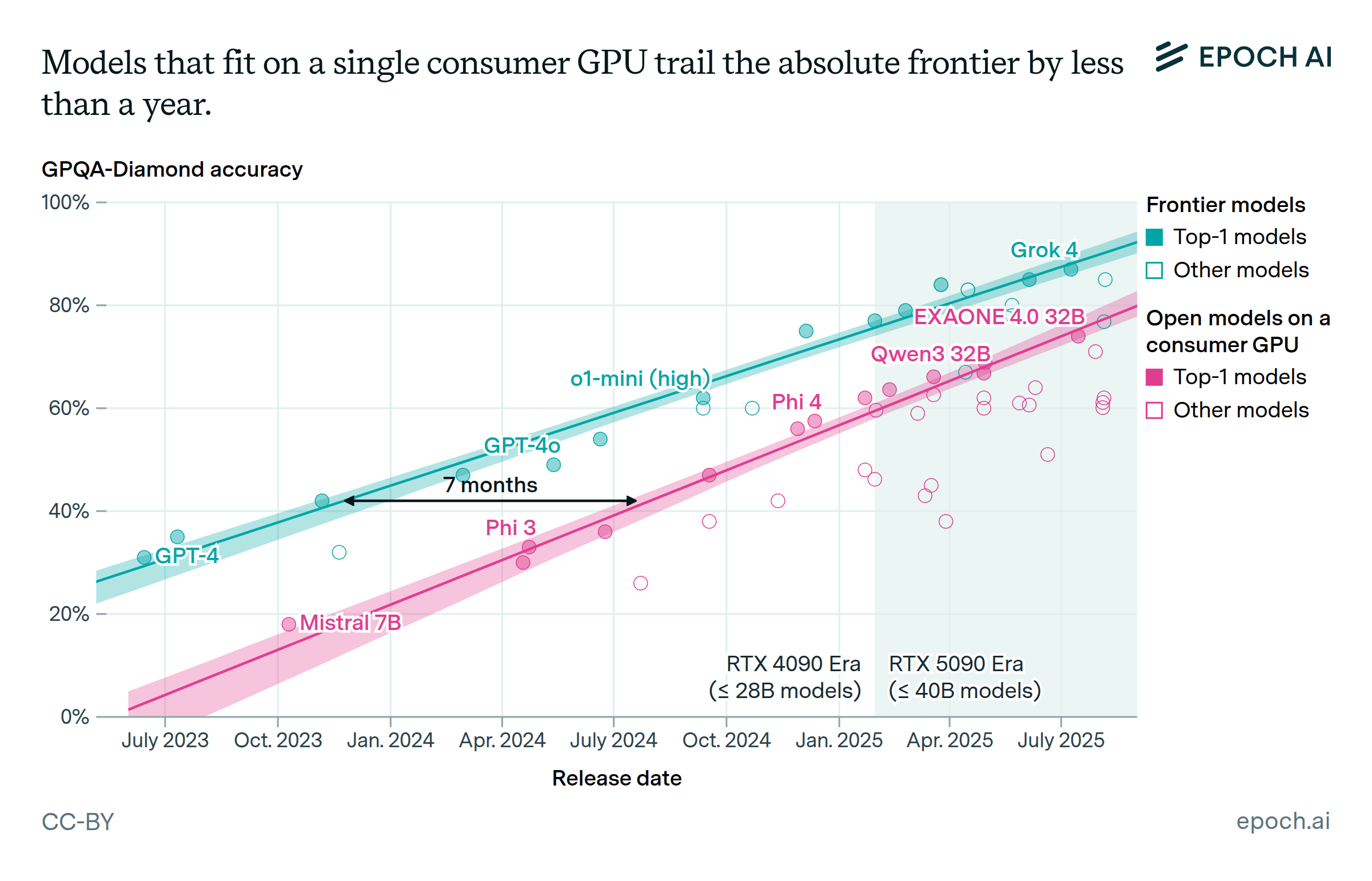
Open models match the capabilities of closed models with a 6-12 month lag
We looked at GPQA Diamond, MMLU -Pro, AA Intelligence and LMArena for Frontier models and open models. Across all four benchmarks we analyzed, models small enough to run on a single consumer GPU (≤28B params for RTX 4090, ≤40B for RTX 5090) consistently catch the frontier within 6-12 months. 1
Why the quick catch-up?
Open-weight models are scaling compute at a rate similar to the closed frontier.
Techniques like distillation compress larger models with minimal performance loss.
New GPU generations increase the size of models that fit locally
Beyond implications for researchers, hobbyists, and small orgs, this trend also bears on AI safety and governance. Any dangerous capabilities appearing at the frontier are likely to be widely available and unrestricted in under a year, complicating regulatory options.
If the roughly year-long lag holds, we expect to see open source models that can be run at home matching the performance of Grok 4 by mid-2026.
This Data Insight was written by Venkat Somala and Luke Emberson. You can learn more about the analysis and explore the interactive figure on our website.
One note of caution: Compared to frontier models, the best-scoring open model for any given benchmark is more likely to be overfit. This means the lag in broad, real-world utility is likely longer than our prediction. As a rough approximation, gpt-oss-20B might be comparable to o1-mini (11 month gap) or Claude 3.5 Sonnet (13 month gap).
 | A guest post by
|
 | A guest post by
|