
What do “economic value” benchmarks tell us?
These benchmarks track a wide range of digital work. Progress will correlate with economic utility, but tasks are too self-contained to indicate full automation.
This article was originally posted on our website at Epoch.ai, together with a full report.
Can AI do real digital work? We reviewed three benchmarks to find out: Remote Labor Index (RLI), GDPval, and APEX-Agents.
Our take: progress here will indicate substantial economic value, but tasks are too self-contained to tell us about wholesale automation.
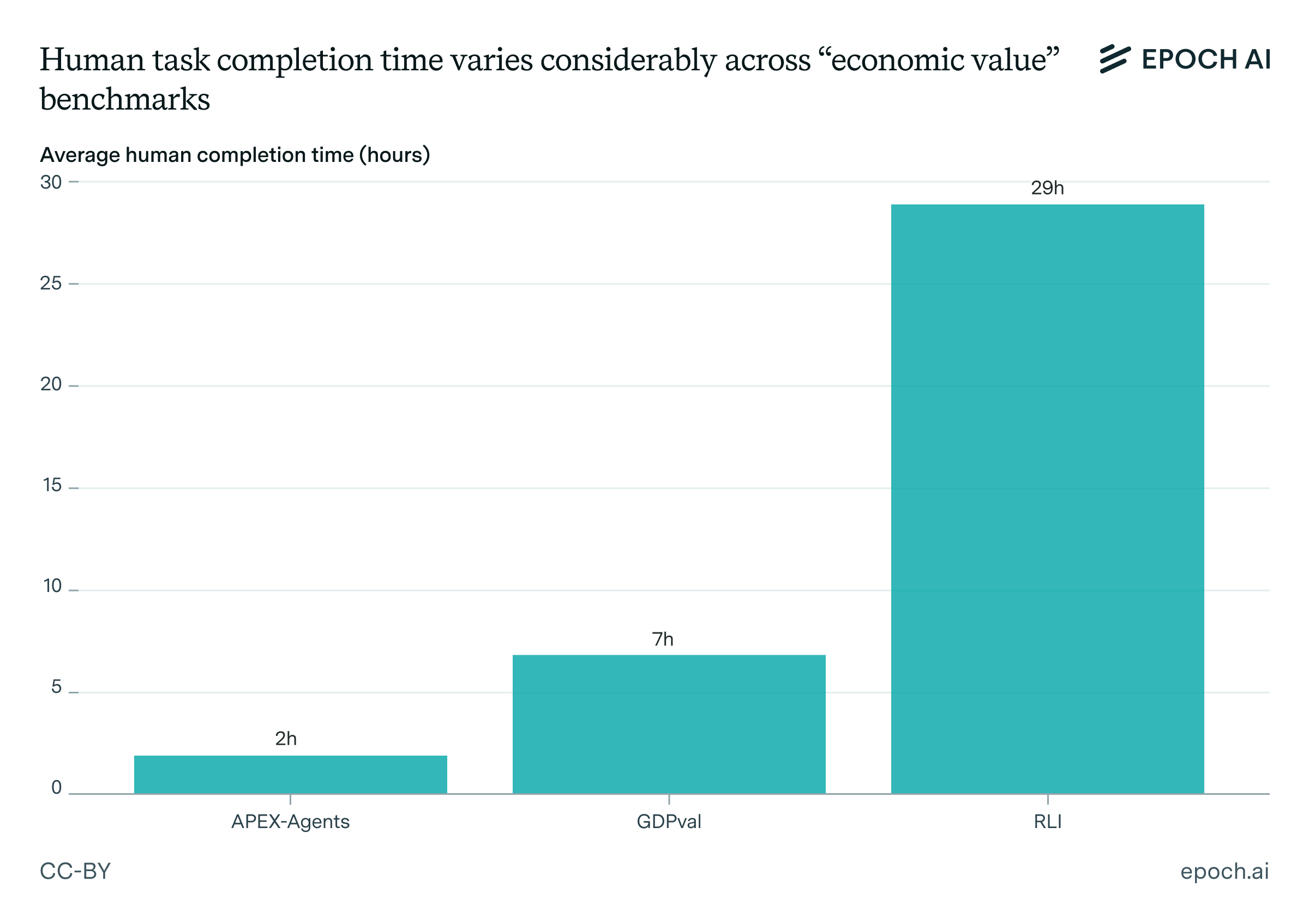
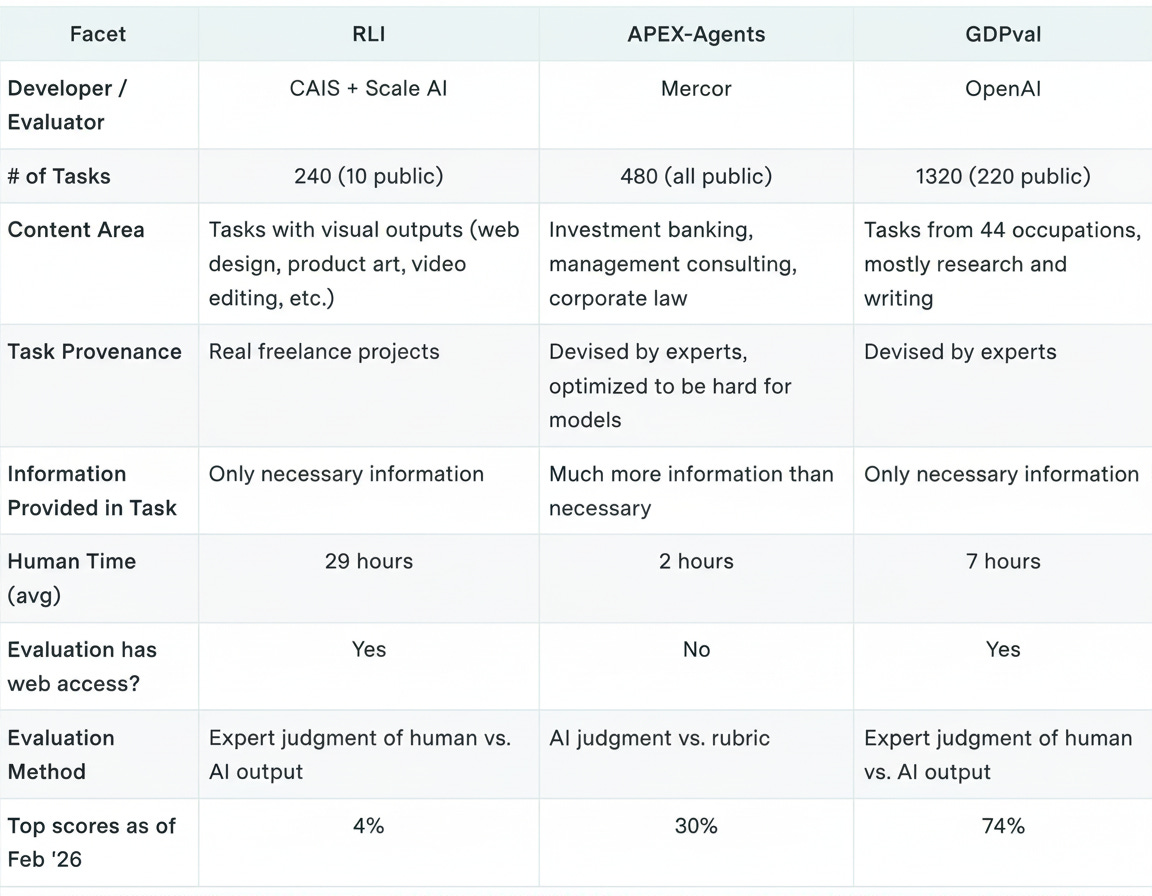
Remote Labor Index (RLI) uses real projects from Upwork. It’s mostly multimedia, from interior design renderings to custom musical arrangements. It’s also the most complex of the three, with average human completion time at 29 hours. Models score very low, partly due to the evaluation scaffold.
APEX-Agents focuses on high-end white collar work. Agents must navigate messy file systems to complete banking, consulting, and legal tasks. Expert humans take 2 hours on average. Current top scores are 30%, and again the scaffold could be improved.
GDPval has the greatest breadth, drawing from 9 industries and 44 occupations. Humans take 7 hours on average. Models have come the farthest here, with top scores at least in the mid-70s. Tasks here are the most unrealistically “clean” in their presentation.
Think of these benchmarks like SWE-bench Verified. Progress means models can do well-defined digital work tasks mostly autonomously, not that they can function as drop-in replacements.
See the full report for much more!
 | A guest post by
|