



Hello! In this edition of the Epoch AI brief:
We’ve released a new dataset and paper on trends in supercomputers!
In a new report, we analyzed SWE-bench Verified, a benchmark testing AI’s real-world coding abilities and its limitations.
We published a paper investigating how speed trades off against cost in language model inference.
We’ve created an interactive tool to explore how the number of models that exceed a given compute threshold is likely to change over time.
We have a host of new Data Insights, distilling trends in supercomputers, benchmark performance, and more!
We’ve published seven new Gradient Updates, covering issues ranging from the case for multi-decade AI timelines to whether AI is already superhuman at FrontierMath.
Our director, Jaime Sevilla, explains how Epoch’s mission has evolved over time.
We’re hiring for two roles: Head of Web Development and an Engineering Lead, Benchmarks.
Latest Publications
Trends in AI Supercomputers

We curated a dataset of over 500 AI supercomputers (sometimes called GPU clusters or AI data centers) from 2019 to 2025 and analyzed key trends in performance, power needs, hardware cost, and ownership. Some key findings:
Computational performance grew 2.5x/year, driven by using more and better chips in the leading AI supercomputers.
Power requirements and hardware costs doubled every year. If current trends continue, the largest AI supercomputer in 2030 would cost hundreds of billions of dollars and require 9 GW of power.
The rapid growth in AI supercomputers coincided with a shift to private ownership. In our dataset, industry owned about 40% of computing power in 2019, but by 2025, this rose to 80%.
The United States dominates AI supercomputers globally, owning about 75% of total computing power in our dataset. China is in second place at 15%.
To learn more, you can read our article and paper, or explore the full dataset yourself!
How Many AI Models Will Exceed Compute Thresholds?
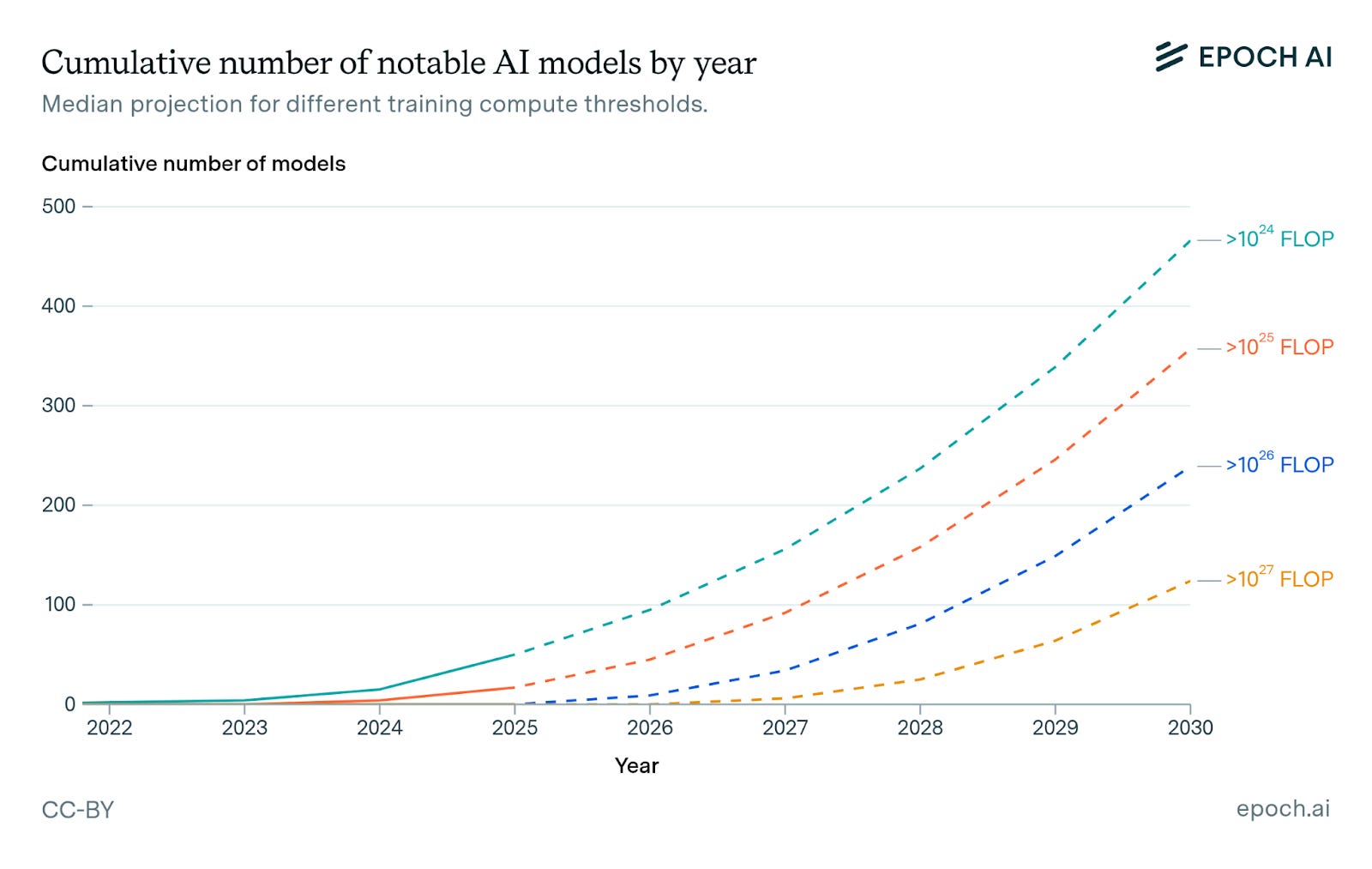
We developed an interactive tool to better understand how the number of notable models—models that are state-of-the-art, highly-cited, or historically significant—that exceed certain compute thresholds applicable to training runs is likely to change over time. Such projections are highly relevant for AI regulation, and to understanding what the future of AI might look like more broadly.
Our model takes key inputs like compute investment and the distribution of compute to arrive at a range of projections. We find that the number of notable AI models above a given compute threshold rapidly accelerates over time. For example, the first model in our dataset estimated to use over 1e26 FLOP was Grok-3 from xAI, released in February 2025. Extrapolating current trends, there would be around 30 such models by the start of 2027, and over 200 models by the start of 2030.
To illustrate the range of plausible model counts through 2030, we developed two alternative scenarios to the median, denoted as “conservative” and “aggressive”. These scenarios are defined by three inputs: investment in the largest training run, total number of models per year, and number of models near the largest training run.
The conservative and aggressive scenarios predict about 10 and 80 notable models above 1026 FLOP by 2027, respectively. This highlights our uncertainty, while affirming that model counts are likely to grow rapidly.
You can learn more in our report, or by playing with our interactive tool.
What skills does SWE-bench Verified evaluate?

We took a deep dive into SWE-bench Verified, a key benchmark testing AI’s agentic coding abilities in real-world contexts. We found that it's one of the best tests of AI coding, but limited by its focus on simple bug fixes in familiar repositories.
SWE-bench Verified mainly tests the ability of models to navigate a Python codebase and fix well-defined, small issues with clear descriptions. It is a much more realistic test for agentic coding than benchmarks that evaluate models on isolated LeetCode-style problems.
However, all the codebases and their respective issues used in SWE-bench Verified are openly available. This means models are likely familiar with these codebases, and there is a high risk of contamination. The low diversity of codebases (with five repositories accounting for >80% of the benchmark samples) and the age of some of these issues are another aspect to be aware of.
Overall, SWE-bench Verified does not capture the full spectrum of software engineering work. However, saturation of this benchmark would strongly indicate that models can autonomously fix small to medium Python issues. Learn more in our full report.
Inference economics of language models

A few years ago, the benchmark for whether a language model was fast enough was “human reading speed”. Now, as models are placed inside elaborate agentic loops, this benchmark has become obsolete. The benefits to serving models faster for inference are greater than ever before. Despite this, there has been little work investigating how language models can be served quickly at scale and how much we can increase their speed at the expense of paying a higher price per token.
Today, we’re releasing a model of LLM inference economics which helps answer these questions. Working with the model reveals many important facts about inference at scale:
Network latency is a critical bottleneck to fast LLM inference.
The token generation speed at which a dense Transformer can be served for inference scales roughly with the inverse square root of its parameter count, and with the cube root of the memory bandwidth of the GPUs used to serve the model.
In practice, the only reason to use pipeline parallelism over data parallelism is to fit a large model into GPU high-bandwidth memory.
Speculative decoding can double the speed of inference with large models without increasing costs or decreasing performance.
We hope that this work will help improve public understanding of the topic and clear up popular misconceptions. Read the paper and our summary blog post here.
Data Insights

Our Data Insights offer digestible snapshots of complex trends in AI. Since April, we’ve published nine new insights. Here’s what we’ve found:
LLM providers offer a trade-off between accuracy and speed.
Power requirements of leading AI supercomputers have doubled every 13 months.
Private-sector companies own a dominant share of AI supercomputers.
The US hosts the majority of AI supercomputers, followed by China.
Acquisition costs of leading AI supercomputers have doubled every 13 months.
Widespread adoption of new numeric formats took 3-4 years in past cycles.
The computational performance of leading AI supercomputers has doubled every nine months.
LLM responses to benchmark questions are getting longer over time.
The combined revenues of leading AI companies grew by over 9x in 2023-2024.
Gradient Updates
Since our April newsletter, we’ve published eight new issues of Gradient Updates, our weekly newsletter containing shorter-form research and commentary on important issues on AI:
Do the biorisk evaluations of AI labs actually measure the risk of developing. bioweapons?
Beyond benchmark scores: Analyzing o3-mini’s mathematical reasoning.
Organizational Updates
What is Epoch?
Epoch’s director Jaime Sevilla shared his thoughts on how Epoch’s work has evolved in the three years since our inception, as well as on how we choose what to prioritize. You can read his take here.
To better communicate our goals and intentions, we are also working on revamping our mission and principles—so stay tuned!
Careers
We’ve decided to split the Chief Technology Officer role, for which we were previously hiring, into two distinct positions:
Head of Web Development. The role entails working to align our tech stack with our long-term goals. Responsibilities will include managing a team of 3-5 engineers and overseeing our full tech stack and infrastructure.
Engineering Lead, Benchmarking. We’re looking for a senior engineer to help us provide independent evaluations of leading AI models, enabling researchers, developers, and policymakers to better understand AI development.
Both positions are fully remote, and applications are rolling, so we encourage you to apply as soon as possible if you think you could be a good fit! We also welcome referrals and offer a $5,000 referral reward. Feel free to reply to this email to refer someone, or email careers@epoch.ai! Find the T&C here.