
Solving AI’s power problem with decentralized training
Conventional wisdom in AI is that large-scale pretraining needs to happen in massive contiguous datacenter campuses. But is this true?
Our research suggests that conducting 10 GW training runs across two dozen sites — linked by a network spanning thousands of km — is feasible.

Using underutilized generation as a proxy of power availability, we identify a 4,800 km network of 23 sites in the U.S. that could theoretically support a 10GW distributed AI cluster, helping to alleviate power bottlenecks.
To use such a distributed cluster for training, we consider fully synchronous data parallelism. In this setup, each site will process a part of each training batch, and then synchronize to update model weights in unison. This strategy has been tested before by NVIDIA to train a Nemotron-4 340B model between two datacenters 1,000km apart.
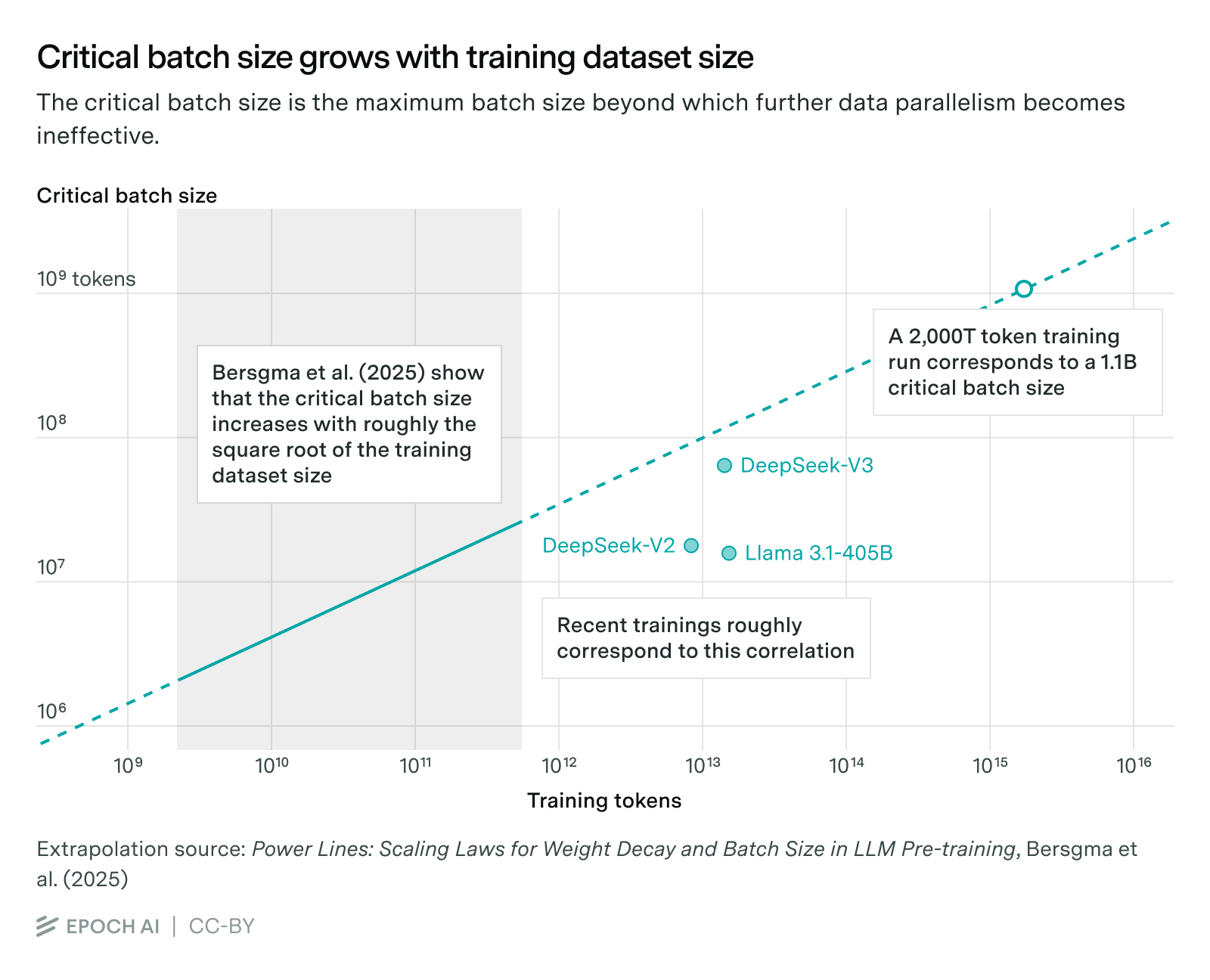
Such a setup will only be practical if the time spent synchronizing is sufficiently small compared to the time it takes to process each batch. The best public work on determining the critical batch size we are aware of is from Bersgma et al. (2025), who posit that the critical batch size increases with roughly the square root of the training dataset size.
For synchronization, we will consider a bidirectional ring all-reduce algorithm. This allows us to complete a synchronization with a single round trip around the network. The synchronization time is then determine by the point-to-point network bandwidth, and bounded by the network latency.

Achieving sufficient bandwidth to keep synchronization time under control sounds daunting. We estimate that to train 72T-parameter models we would need over 25x the bandwidth of the MAREA transoceanic fiber cable — the highest-capacity internet cable crossing the Atlantic. However, the main cost of fiber deployment is installation, so increasing bandwidth is cheap compared to the overall cost of datacenter construction.

The bottom line
Conducting large decentralized training runs is feasible without a large increase in either training time or budget.
However, distributed clusters have many downsides:
more complex permitting processes
additional engineering to manage a long-range network connection and reliability
constraints on communication-heavy paradigms
We expect that AI companies will prefer to scale AI campuses as much as they can, and only resort to distributed clusters to go beyond the scale that utilities are willing to provide through the grid.
Evidence for this is Microsoft’s Fairwater datacenter in Wisconsin, a planned multiple GW site that will allegedly become “part of a global network of Azure AI datacenters”— meant to “enable large-scale distributed training across multiple, geographically diverse Azure regions”.
Find detailed analysis, calculations and sources in the full article on our website.
 | A guest post by
|