
GPT-5.1 is about as capable as GPT-5
With “high” reasoning, both GPT-5.1 and GPT-5 score 151 on the Epoch Capabilities Index, our tool for combining results across multiple benchmarks

For the benchmarks we run ourselves, scores of the two models are all within the margin of error of each other.
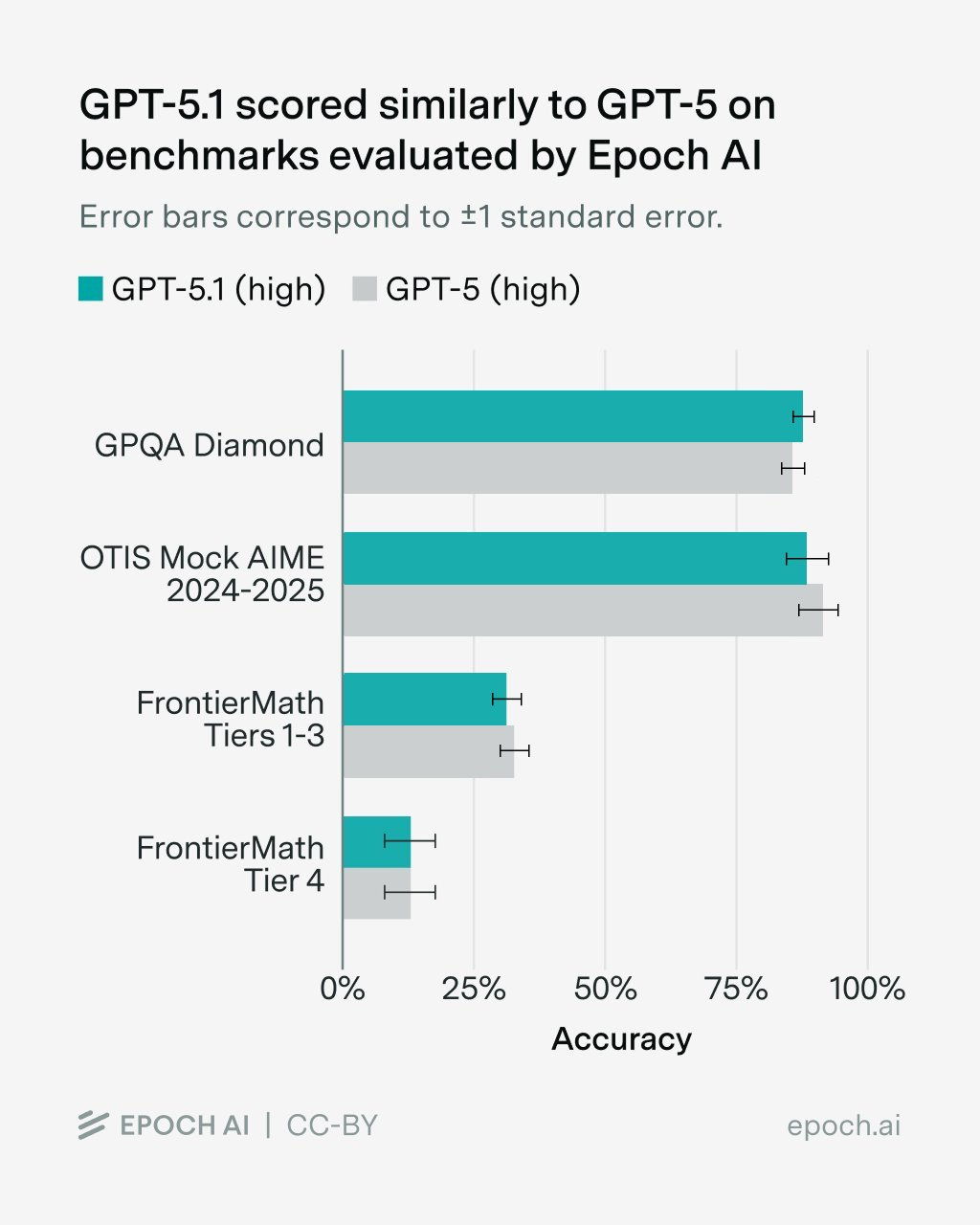
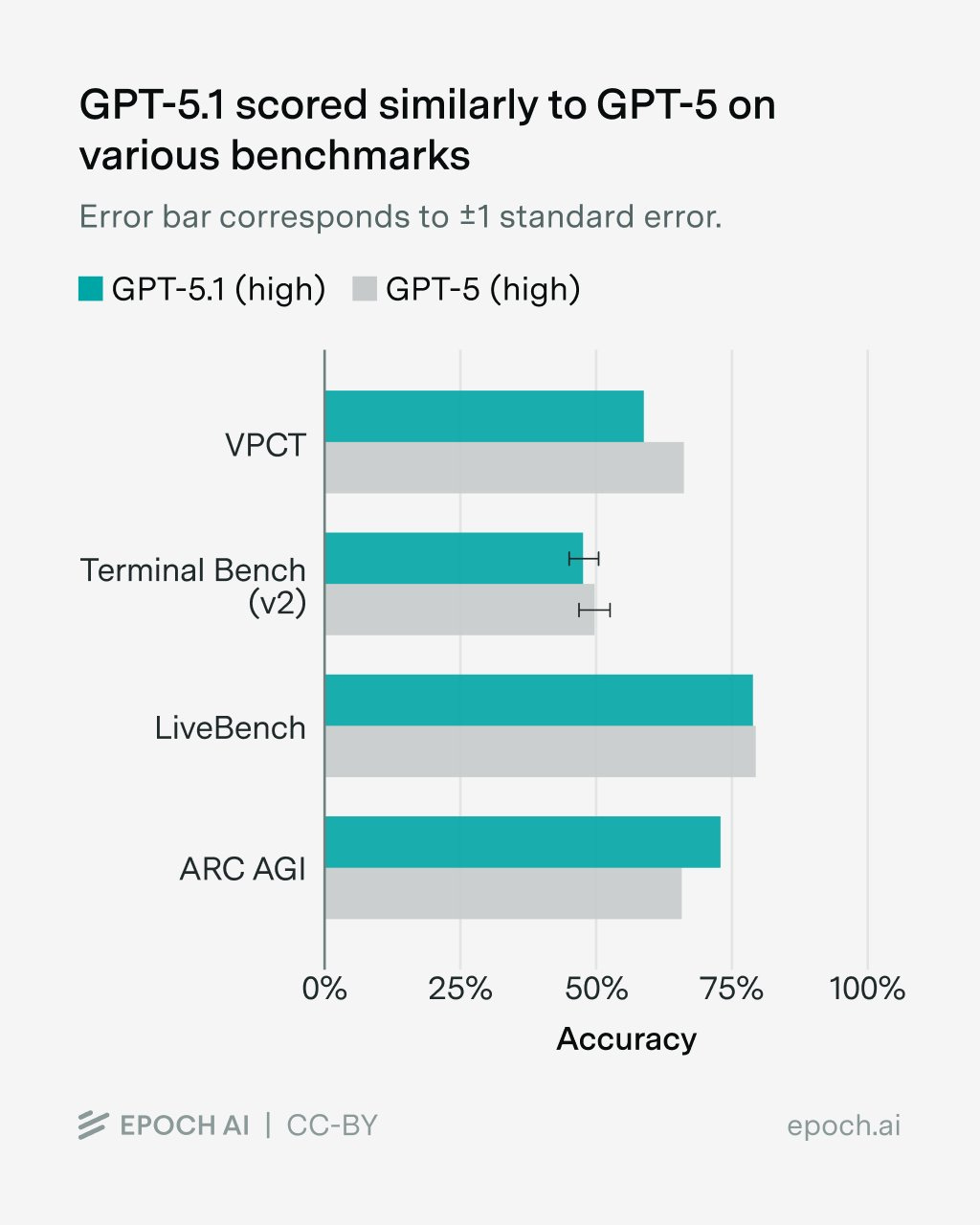
ECI also incorporates benchmarks run by others. We see a similar picture of broadly comparable scores across these benchmarks.
OpenAI described GPT-5.1 as spending “less time on easy tasks and more time on hard tasks” compared to GPT-5. Assuming our benchmarks count as “hard tasks”, this appears to be true.
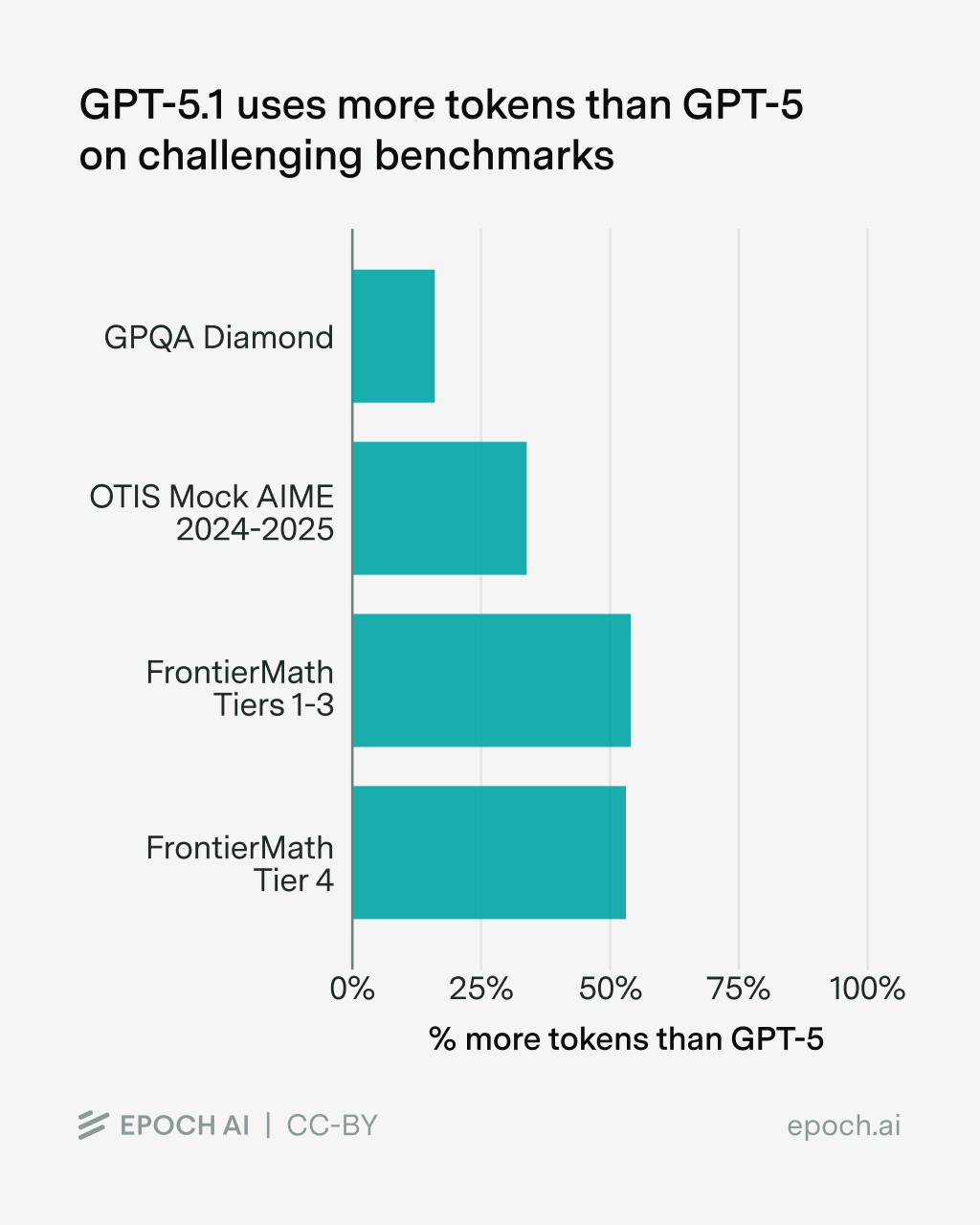
Thus, GPT-5.1 joins GPT-5 at the frontier but, despite greater token use, does not improve on the capabilities these benchmarks measure.
Check out our website for all this and more!