
Epoch’s Capabilities Index stitches together benchmarks across a wide range of difficulties
Interpreting our new capabilities index
The Epoch Capabilities Index is a useful way to measure model capabilities, but what does a score of 150 actually mean?
One way to read our new capability index is by plotting the benchmark performance you expect to see, for a range of ECI scores.
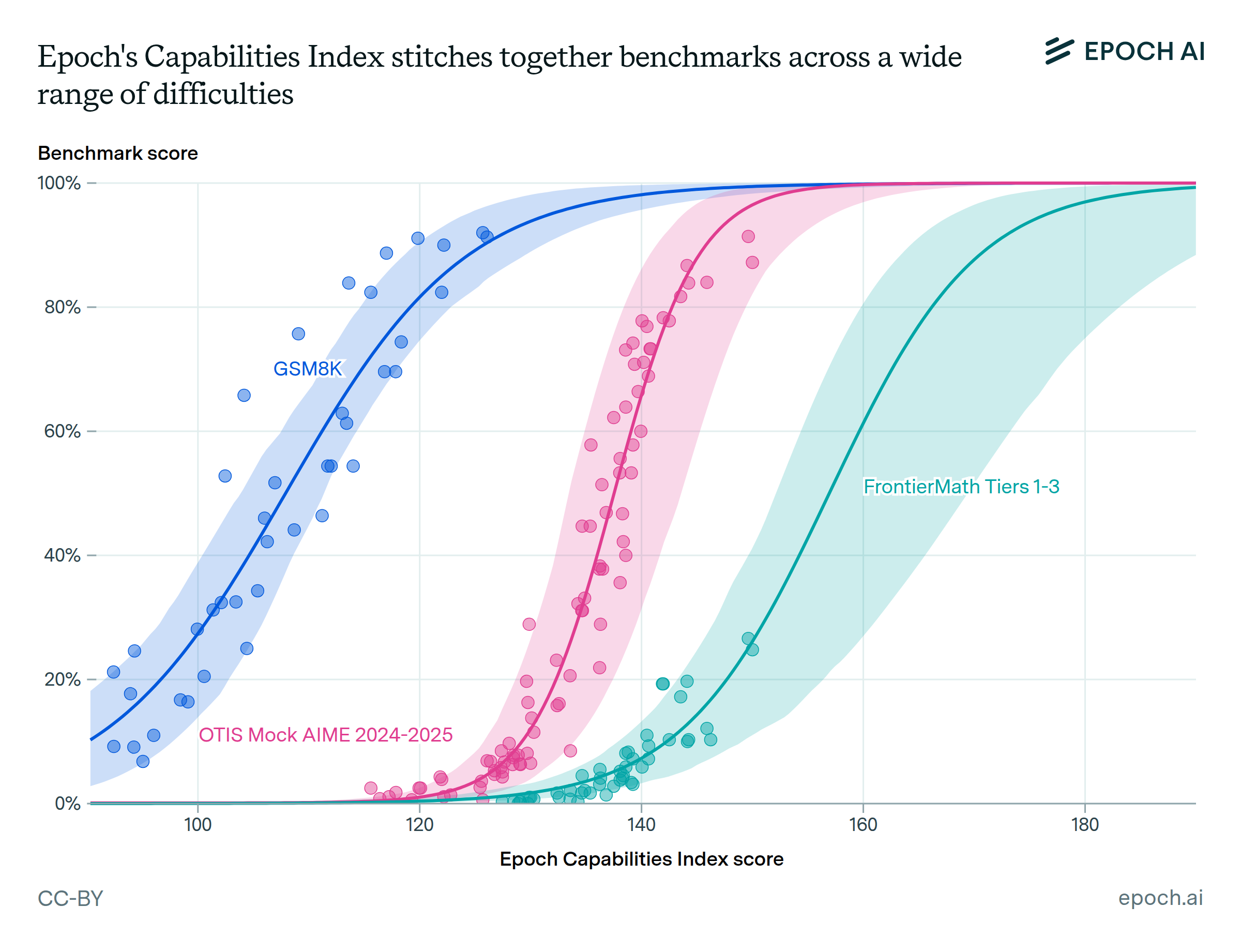
Three important takeaways:
1. Benchmarks vary in overall difficulty, and in slope. Steeper slopes imply a narrower range of difficulties at the question level, and mean the benchmark saturates quickly once some progress is made.
2. While a model with a score of 140 is expected to get 45% on SWE-Bench Verified, this is just an expectation. Individual models perform better or worse on specific tasks. For instance, GPT-5 underperforms in GPQA Diamond, but overperforms in VPCT.
3. We’re quite uncertain about the difficulty of some benchmarks.
No model has scored more than 29% on FrontierMath, so saturating it definitely requires more than the current SOTA of 150... but will it take an ECI of 175? 200? For now, it’s hard to be sure.
We’re excited to do more work tying ECI to concrete metrics. For now, check out details about this insight on our website.